Claude Haiku vs Local Models: The Real Tradeoff

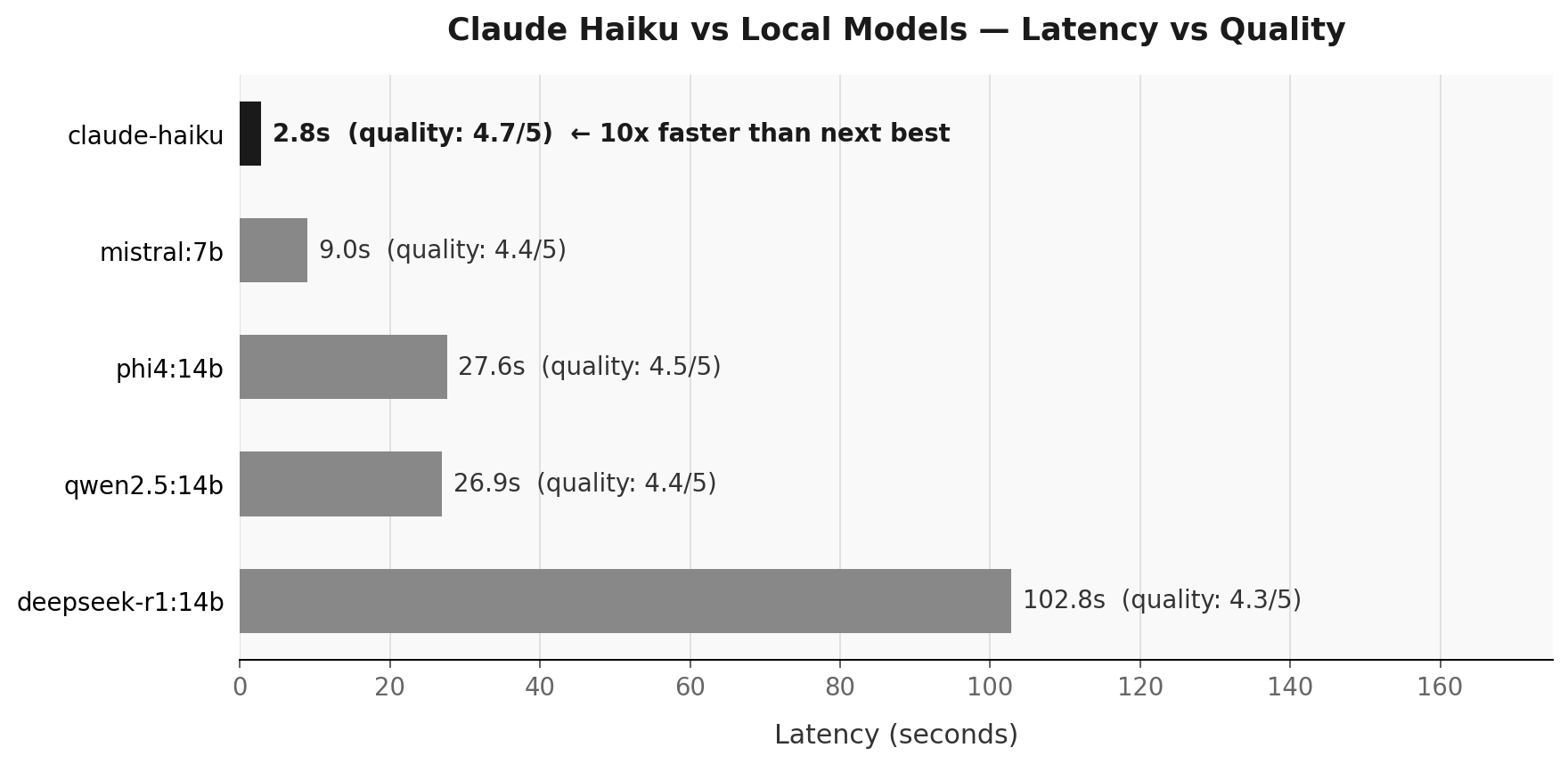
27.6 seconds vs 2.8 seconds. That gap isn't a benchmark footnote — it's the difference between a product people use and one they abandon.
I was building AskS1.com, a RAG system for querying the SpaceX S-1. The generation step — taking retrieved chunks and producing a cited answer — needed to be fast enough that someone would actually wait for it. I benchmarked five models to find out which one earned that spot: Claude Haiku, and four 7-14B local models running on a Mac Mini M4 via Ollama.
The overall numbers looked like a rounding error. The category breakdown told a different story.
How I Evaluated
15 questions across three categories, same retrieved context for every model.
Factual recall — can the model extract a specific number correctly?
"What is SpaceX's total revenue for 2025?"
"How many Starlink subscribers does SpaceX have as of Q1 2026?"
"What is SpaceX's total debt as of Q1 2026?"Multi-step reasoning — does the model connect information across sections and form a judgment?
"Why is SpaceX's AI segment consuming 62-76% of capex but generating
only 17% of revenue? Is this a concern?"
"Why can't Elon Musk be removed as CEO without his own approval?"
"How does SpaceX's vertical integration give it an advantage?"Structured output — can the model follow formatting instructions precisely?
"Summarize SpaceX's three business segments in a markdown table
with columns: Segment, Revenue, Operating Income, Key Product."
"List the top 5 risk factors in order of severity."
"Summarize Elon Musk's compensation structure in exactly 4 bullets."One factual question was a deliberate curveball — "What RL algorithm does DeepSeek use?" — unrelated to SpaceX entirely, testing whether models would admit "I don't know" or hallucinate an answer just because the context was about a tech company.
Scoring
Two methods for two question types.
Factual recall — scored against ground-truth figures pulled directly from the filing. Exact numbers, keyword matching — does the answer contain the correct revenue figure, subscriber count, debt number.
Reasoning and structured output — scored 1-5 by Claude Sonnet as an LLM judge, evaluating coherence, accuracy, and instruction-following. These don't have single correct answers — "is this sustainable?" requires judgment, not pattern matching.
The Results
Model Overall Factual Reasoning Structured Latency
claude-haiku 4.7 5.0 4.8 4.4 2.8s
phi4:14b 4.5 4.4 4.5 4.6 27.6s
qwen2.5:14b 4.4 4.4 4.2 4.6 26.9s
mistral:7b 4.4 4.4 4.0 4.6 9.0s
deepseek-r1:14b 4.3 4.4 3.8 4.6 102.8sA 0.2-4.4 point spread on a 5-point scale looks like noise. It isn't — it's three different stories stacked on top of each other.
Where the Gap Actually Lives
Structured output: local models win. Every local model scored 4.6, ahead of Haiku's 4.4. Following "exactly 4 bullets" or "markdown table with these columns" doesn't require deep reasoning, and the local models were if anything slightly more literal about compliance.
Reasoning: this is where the real gap is. Haiku scored 4.8. deepseek-r1:14b scored 3.8 — a full point lower, despite taking 102.8 seconds per question, 37x Haiku's latency. These questions asked models to connect numbers across sections and form a judgment — "ARPU is declining but revenue is growing — is this sustainable, and why?" This is where size and training quality actually show up. Interestingly, phi4:14b (4.5) and qwen2.5:14b (4.2) — both 14B — outperformed deepseek-r1:14b (3.8) despite being the same size class. Reasoning quality isn't just a parameter-count story.
Factual recall: one question did almost all the damage. Four of five factual questions, every model scored a perfect 5.0. The entire gap traces to one question — "How many Starlink subscribers does SpaceX have as of Q1 2026?" All four local models answered "10,300 thousand (or 10.3 million)" — numerically correct, but the "10,300 thousand" phrasing tripped the keyword scorer. Haiku said "10.3 million" cleanly and scored full marks. Not a knowledge gap. A units-formatting quirk that cost 2.3 points on one question out of fifteen.
So the honest summary: for structured tasks, local models are competitive or better. For reasoning, there's a real gap, and it scales with model quality more than raw size. For factual recall, the "gap" was mostly an artifact of how I scored one question.
(And for the DeepSeek curveball — Haiku, phi4, qwen2.5, and deepseek-r1 all correctly said "I don't know." mistral:7b confidently described "DeepSeak, a spacecraft navigation autonomous docking system developed by SpaceX" — a system that does not exist. A small reminder that "I don't know" is sometimes the only correct answer, and not every model knows that.)
The Cost Angle
Estimating cost per query for both:
Claude Haiku — roughly 2,900 input tokens (context + system prompt + question) and ~400 output tokens per query comes to about $0.004 per query.
Mac Mini M4 electricity — 27.6 seconds at ~25W draw works out to about $0.00006 per query — roughly 65x cheaper than the API call, in pure electricity terms.
Neither number matters at the scale of a side project. The Mac Mini is "free" because I already own it. The API cost is "free" because it's a fraction of a cent. Cost only becomes the deciding factor at high query volume — thousands of requests per day, where $0.004 × 10,000 = $40/day starts to add up against hardware you already paid for once.
So When Do Local Models Make Sense?
Not "Haiku wins, always." Local models make sense when:
- Privacy matters — documents that can't leave your machine
- Offline access is required — no network dependency
- Volume is high enough that per-query API cost compounds meaningfully
- Latency tolerance is high — batch processing, overnight jobs, anything where 27 seconds vs 2.8 seconds doesn't matter to a human waiting
For AskS1.com — a public tool where someone types a question and waits — 2.8 seconds is the only viable answer. But for the private Google Drive knowledge base I built on the same Mac Mini, the calculus flips entirely: nothing leaves my machine, nobody's waiting in real time, and the documents are mine. Local models there aren't a compromise — they're the right tool.